1.Abstract&Info
1.1 Abstract
Existing state-of-the-art dense object detection techniques tend to produce a large number of false positive detections on difficult images with complex scenes because they focus on ensuring a high recall. To improve the detection accuracy, we propose an Adaptive Important Region Selection (AIRS) framework guided by Evidential Q-learning coupled with a uniquely designed reward function. Inspired by human visual attention, our detection model conducts object search in a top-down, hierarchical fashion. It starts from the top of the hierarchy with the coarsest granularity and then identifies the potential patches likely to contain objects of interest. It then discards non-informative patches and progressively moves downward on the selected ones for a fine-grained search. The proposed evidential Q-learning systematically encodes epistemic uncertainty in its evidential-Q value to encourage the exploration of unknown patches, especially in the early phase of model training. In this way, the proposed model dynamically balances exploration-exploitation to cover both highly valuable and informative patches. Theoretical analysis and extensive experiments on multiple datasets demonstrate that our proposed framework outperforms the SOTA models.
1.2 Info
Authors: Dingrong Wang, Hitesh Sapkota, Qi Yu
DOI:
Publication: Advances in Neural Information Processing Systems
PDF: PDF
Zotero: [PDF]
Data: 2024-12-16
2. Annotation
%% begin annotations %%
Imported: 2025-03-08 9:37 晚上
原文:[a large number of false positive detections on difficult images with complex scenes because they focus on ensuring a high recall.]
标注:复杂场景中出现大量FP结果
原文:[Evidential Q-learning coupled with a uniquely designed reward function]
标注:通过强化学习方法来解决
原文:[top-down, hierarchical fashion]
标注:top-down搜索,层级搜索
原文:[from the top of the hierarchy with the coarsest granularity and then identifies the potential patches likely to contain objects of interest.]
标注:由粗糙逐步细化
原文:[the proposed model dynamically balances exploration-exploitation to cover both highly valuable and informative patches]
标注:模型动态平衡了搜索和发现
原文:[In testing, some negative anchors may generate an unusually high-quality estimation score and be selected as positive anchors (i.e., false positives) due to lack of supervision.]
标注:在测试中,某些负锚可能会产生异常高质量的估计评分,并因缺乏监督而被选为正锚(即假阳性)。
原文:[on small objects in a complex background]
标注:复杂背景,小物体中都会出现较多的FP
原文:[in existing onestage detectors does not capture diverse types of candidate anchors residing on the Feature Pyramid Network (FPN)]
标注:所解决的问题存在于单阶段目标检测器中(两阶段是否遇到类似的问题?),问题是无法捕获足够丰富的候选框,造成许多假阳性。
原文:[Evidential Q-learning]
标注:主要方法
原文:[Furthermore, in the early phase of RL agent training, AIRS also encourages the agent to explore highly uncertain patches by leveraging the epistemic uncertainty provided by our evidential Q-value. Exploration of novel patches is also dynamically balanced with the exploitation of predicted high quality region.]
标注:训练早期的时候RL代理会积极鼓励搜索高度不确定性的区域以增强发现能力
原文:[an adaptive hierarchical object detection paradigm supported by an RL agent to mimic human visual attention that performs searching in the top-down fashion,]
标注:RLagenet的动态分层物体检测方法
原文:[novel evidential Q-learning driven by a unique reward function, covering both potentially positive and highly uncertain patches through dynamically balancing exploitation and exploration,]
标注:新的qlearning方法
原文:[theoretical guarantee on the fast convergence of the proposed evidential Q-learning algorithm,]
标注:qlearning的理论保证
原文:[Deep Reinforcement Learning for Object Detection.]
标注:所引用的方式最晚在2021年,其他分别在14,15,16年,相对收到更少的关注
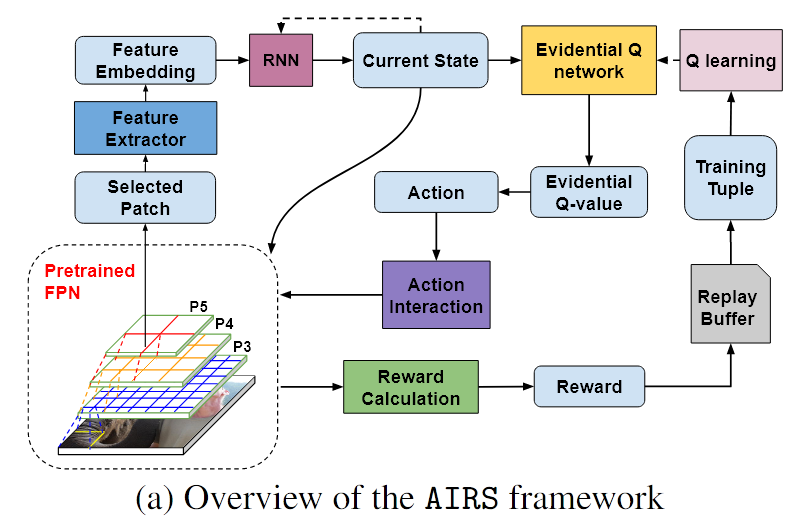
原文:[Once a patch is selected by the RL agent, it is passed through the feature extractor followed by the recurrent neural network (RNN) to generate the state representation.]
标注:步骤1:当某个patch被RL代理选中时,它将被传给RNN以获取状态表现
原文:[he state representation then goes through the evidential Q-network, which formulates an evidential Normal-inverse Gaussain (NIG) distribution and outputs the Q-value estimate for each available action.]
标注:步骤2:状态表现被传给Qnet,,生成NIG分布和Q值
原文:[Then by combining with the corresponding epistemic uncertainty in the Q-value estimate, we have the evidential Q-value which balances the estimated Q-value with the (lack of) knowledge of the RL agent on the chosen action.]
标注:步骤3:结合Q值估计中的认知不确定性,获取该动作(选择patch)的基于证据的Q值
原文:[Based on the evidential Q-value obtained by balancing epistemic uncertainty and estimated Q-value, the agent takes action, and then selects the next patch with the goal of maximizing the expected reward.]
标注:步骤4:基于该eQ值,代理执行动作,并选择下一额patch以最大化回报
原文:[]
标注:
原文:[]
标注:
原文:[]
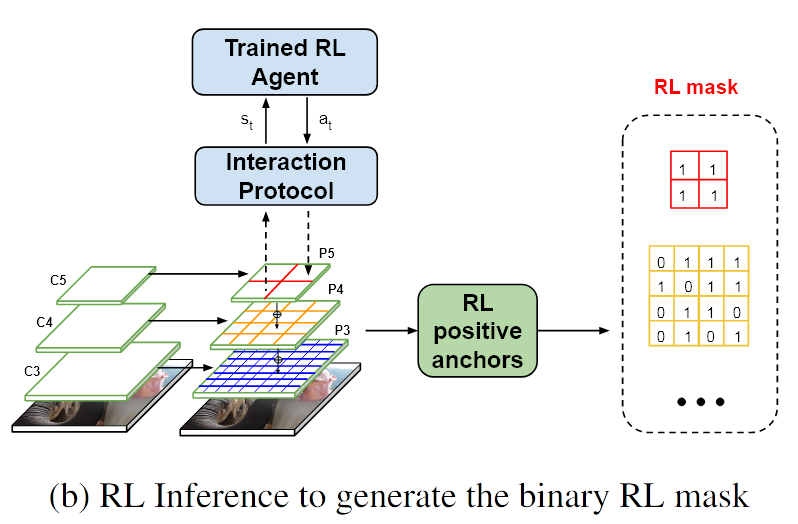
标注:具体来说,每个被选择的patche与上一个状态s(t)结合输入到RNN中,得到下一个状态s(t+1)
原文:[Let D denote the size of the action space.]
标注:动作空间为D
原文:[]
标注:eQLearning的过程。会在后期追加
原文:[The action interaction module translates the action into the location of the next patch to be selected.]
标注:动作交互模块将动作翻译为如何下一个选择的patch为hi
原文:[]
标注:动作D维度的向量中,前D-1表示向下动作,最后一个代表向上动作。
原文:[For downward movement actions, we compute the reward based on the ranking of the patch selected by the movement action compared to all other patches located on the same layer in terms of the number of the positive anchors they contain.]
标注:对于向下动作,会将其选择的patch与包含正锚的patch做对比,其匹配的大小作为回报
原文:[Specifically, we compute the quality measure estimate of each anchor by investigating a range of metrics: centerness [38], IoU[32], GIoU[34], and DIoU [46].]
标注:匹配方法:centerness, IOU,GIoU,DIoU
原文:[In addition, we set up a penalty term with the downward movement in each time step representing the searching cost.]
标注:此外,设置了一个惩罚期限,每个时间步骤的向下移动代表搜索成本。
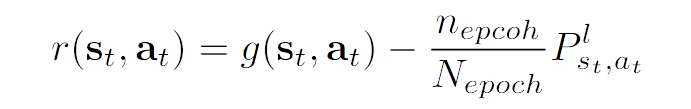
原文:[]
标注:回报公式,包括匹配分数和时间成本
原文:[For upward movement, the reward is simply set to 0,]
标注:向上动作无回报,考虑到向上总是有确定结果的
%% end annotations %%
%% Import Date: 2025-03-08T21:37:49.617+08:00 %%