1.Abstract&Info
1.1 Abstract
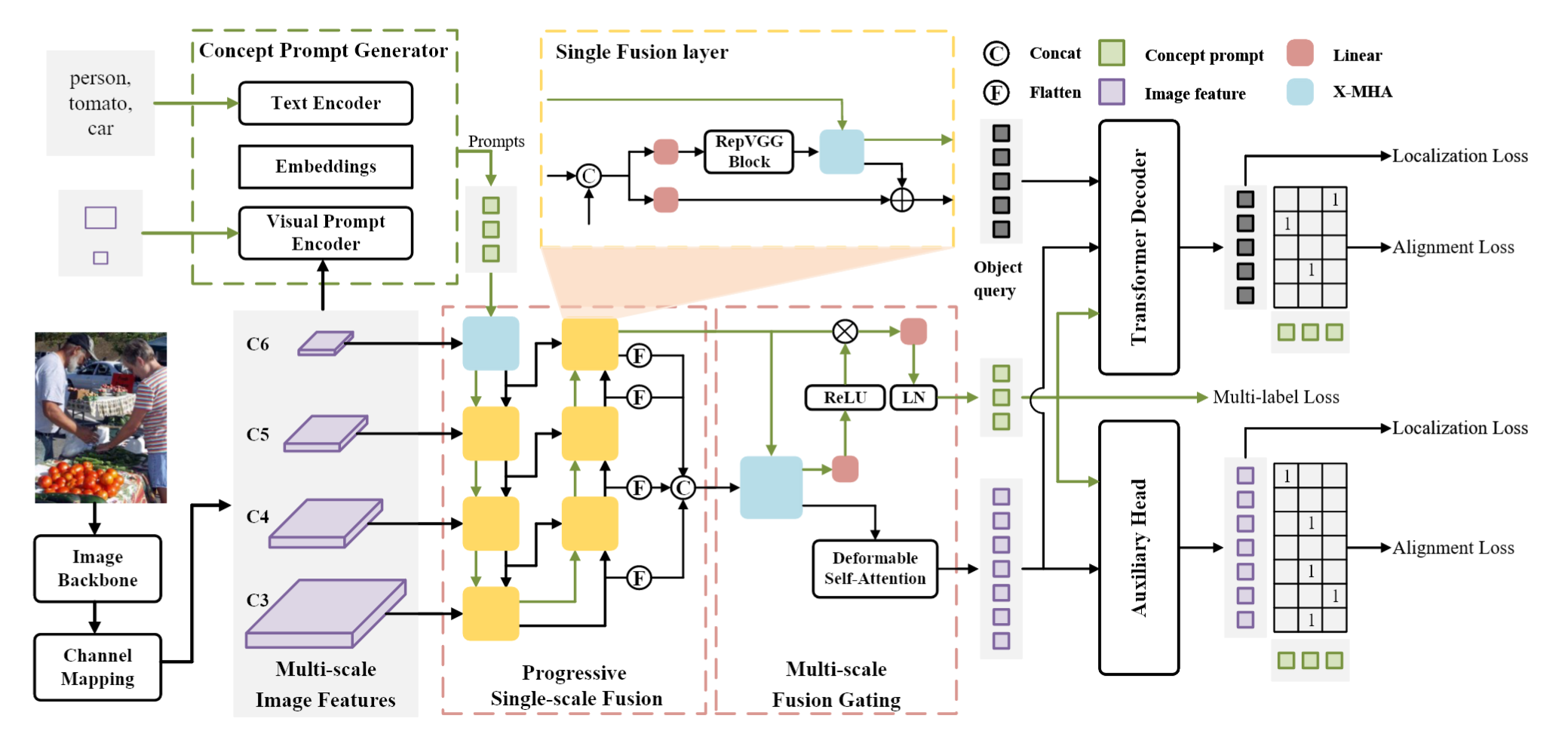
Recent research on universal object detection aims to introduce language in a SoTA closed-set detector and then generalize the open-set concepts by constructing large-scale (text-region) datasets for training. However, these methods face two main challenges: (i) how to efficiently use the prior information in the prompts to genericise objects and (ii) how to reduce alignment bias in the downstream tasks, both leading to sub-optimal performance in some scenarios beyond pre-training. To address these challenges, we propose a strong universal detection foundation model called CP-DETR, which is competitive in almost all scenarios, with only one pre-training weight. Specifically, we design an efficient prompt visual hybrid encoder that enhances the information interaction between prompt and visual through scale-by-scale and multi-scale fusion modules. Then, the hybrid encoder is facilitated to fully utilize the prompted information by prompt multi-label loss and auxiliary detection head. In addition to text prompts, we have designed two practical concept prompt generation methods, visual prompt and optimized prompt, to extract abstract concepts through concrete visual examples and stably reduce alignment bias in downstream tasks. With these effective designs, CP-DETR demonstrates superior universal detection performance in a broad spectrum of scenarios. For example, our Swin-T backbone model achieves 47.6 zero-shot AP on LVIS, and the Swin-L backbone model achieves 32.2 zero-shot AP on ODinW35. Furthermore, our visual prompt generation method achieves 68.4 AP on COCO val by interactive detection, and the optimized prompt achieves 73.1 fully-shot AP on ODinW13.
1.2 Info
Authors: Qibo Chen, Weizhong Jin, Jianyue Ge, Mengdi Liu, Yuchao Yan, Jian Jiang, Li Yu, Xuanjiang Guo, Shuchang Li, Jianzhong Chen
DOI: 10.48550/arXiv.2412.09799
Publication:
PDF: Preprint PDF
Zotero: [Preprint PDF]
Data: 2024-12-13
2. Annotation
%% begin annotations %%
Imported: 2025-03-06 10:22 上午
原文:[introduce language in a SoTA closed-set detector and then generalize the open-set concepts by constructing large-scale (textregion) datasets for training. H]
标注:
原文:[how to reduce alignment bias in the downstream tasks, both leading to sub-optimal performance in some scenarios beyond pre-training]
标注:当ood时,同样的任务也可能出现偏差
原文:[we design an efficient prompt visual hybrid encoder that enhances the information interaction between prompt and visual through scaleby-scale and multi-scale fusion modules.]
标注:通过混合编码器增强在提示和视觉之间增强融合
原文:[fully utilize the prompted information by prompt multi-label loss]
标注:多标签生成提示
原文:[auxiliary detection head.]
标注:多任务
原文:[text prompts, we have designed two practical concept prompt generation methods, visual prompt and optimized prompt,]
标注:多种提示,包括文本提示,视觉提示和优化提示
原文:[While using text prompts has been primarily favored in universal detection, they suffer from sub-optimal performance in downstream applications,]
标注:文本提示在下游应用时,面临次等优化(sub-optimal)的情况,比不上专门优化的邻域模型
原文:[matching deficiency, where the detector produces mismatched results with the text description]
标注:过去的uod方法由于检测器产生的误匹配结果造成的匹配缺陷
原文:[Objectively, text descriptions follow a long-tailed pattern and different descriptions can refer to the same image region, so it is impractical to align all the texts and image regions accurately during pretraining.]
标注:客观上,文本描述是长尾的,多种描述可能对应同一区域,因此预训练时对所有文本和所有图像区域准确对其是有效的
原文:[Subjectively, it is difficult for users to accurately describe complex objects, such as specific mechanical devices, through language.]
标注:主观上,用户对于某些物体是难以精准描述的
原文:[The work (Li et al. 2022b) has shown that the early fusion paradigm performs significantly better than the late fusion paradigm after eliminating alignment bias through prompt tuning in the downstream tasks.]
标注:早期融合方法比晚期融合好,前提是通过提示学习在下游任务上进行微调以消除匹配偏差
原文:[Late fusion paradigms (Li et al. 2019) only use prompt vectors in the classification part, the location dependent on pre-training data distributions, which is poor in utilizing prompt information.]
标注:物体检测的后融合方法中只有分类可以得益于后融合,定位还是依赖于预训练模型,这对提示信息的使用是不足的。
原文:[we believe that a key to improving the performance of universal detection lies in achieving effective cross-modal interaction between prompt and visual.]
标注:提示和视觉信息的有效交互是解决通过检测的有效方法
原文:[]
标注:CP-DETR的三种提示包括文本,视觉和优化。奇怪的是视觉信息的加入和优化信息的加入基本等于加入了监督信息,这和zeroshot还是有所区别的,会进一步在下文寻找其和监督学习的区别
原文:[CP-DETR, a model based on the early fusion paradigm that not only supports text prompts but also introduces visual prompts and optimized prompts to address alignment biases beyond pre-training]
标注:CP-DETR不仅仅支持文本提示,也支持视觉提示和优化提示
原文:[Visual prompts avoid misalignment arising from subjective user description errors]
标注:视觉提示避免了缺乏精准描述的问题
原文:[An optimized prompt provides a more direct solution by prompt tuning through downstream data annotation to align regions without changing the pre-training weights]
标注:优化提示通过下游任务的标注来对其区域
原文:[concept prompts to represent these vectors in a unified way and divide the whole model into two parts: detector and concept prompt generation.]
标注:两个部分,检测器和概念提示生成器
原文:[or effective cross-modal interaction, we design an efficient prompt visual hybrid encoder that updates visual and concept prompts via progressive single-scale fusion (PSF) and multi-scale fusion gating (MFG), avoiding confusion due to semantic gaps between different levels of visual features.]
标注:混合编码器
原文:[Due to DETR being a sparse detector framework]
标注:稀疏检测框架为什么要加辅助检测头?
原文:[we added an auxiliary detection head and a prompt multilabel loss to facilitate the hybrid encoder to fully utilize different modal information in the interaction.]
标注:我们添加了一个辅助检测头和一个及时的多标记损失,以促进混合编码器在交互中充分利用不同的模态信息。
原文:[For visual prompt, we design a visual prompt encoder that encodes the bbox as a query and adaptively aggregates concept representations from multi-scale features output by the visual backbone.]
标注:visual prompt是给定bbox从backbone中特征获取的。这合理吗?bbox从那里来的?
原文:[Text Prompted Universal Detection]
标注:一些有用的方法,可以引用
原文:[]
标注:我没有找到这里的box coordinate是如何提供的,如果给到背景,直觉上应该会损害检测结果,如果给到前景,则检测的意义在哪里?
Imported: 2025-03-06 10:22 上午
原文:[]
标注:
%% end annotations %%
%% Import Date: 2025-03-06T10:22:56.837+08:00 %%