1.Abstract&Info
1.1 Abstract
The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we introduce YOLO-World, an innovative approach that enhances YOLO with open-vocabulary detection capabilities through vision-language modeling and pre-training on large-scale datasets. Specifically, we propose a new Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to facilitate the interaction between visual and linguistic information. Our method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed. Furthermore, the fine-tuned YOLO-World achieves remarkable performance on several downstream tasks, including object detection and open-vocabulary instance segmentation.
1.2 Info
Authors: Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan
DOI: 10.48550/arXiv.2401.17270
Publication:
Data: 2024-02-22
2. Annotation
%% begin annotations %%
Imported: 2025-02-21 4:24 下午
原文:[Re-parameterizable VisionLanguage Path Aggregation Network]
标注:核心
原文:[for high-efficiency open-vocabulary object detection]
标注:重点在高效
原文:[YOLO-World follows the standard YOLO architecture [20] and leverages the pre-trained CLIP [39] text encoder to encode the input texts.]
标注:使用CLIP作为文本信息的提供方
原文:[During inference, the text encoder can be removed and the text embeddings can be re-parameterized into weights of RepVL-PAN for efficient deployment.]
标注:训练时将文本信息转入RepVL-PAN,运行时不再依赖CLIP
原文:[the prompt-thendetect paradigm (Fig. 2 (c)) first encodes the prompts of a user to build an offline vocabulary and the vocabulary varies with different needs.]
标注:首先将输入的文本转化为提示,同一词汇在不同场景下产生的提示可能不同
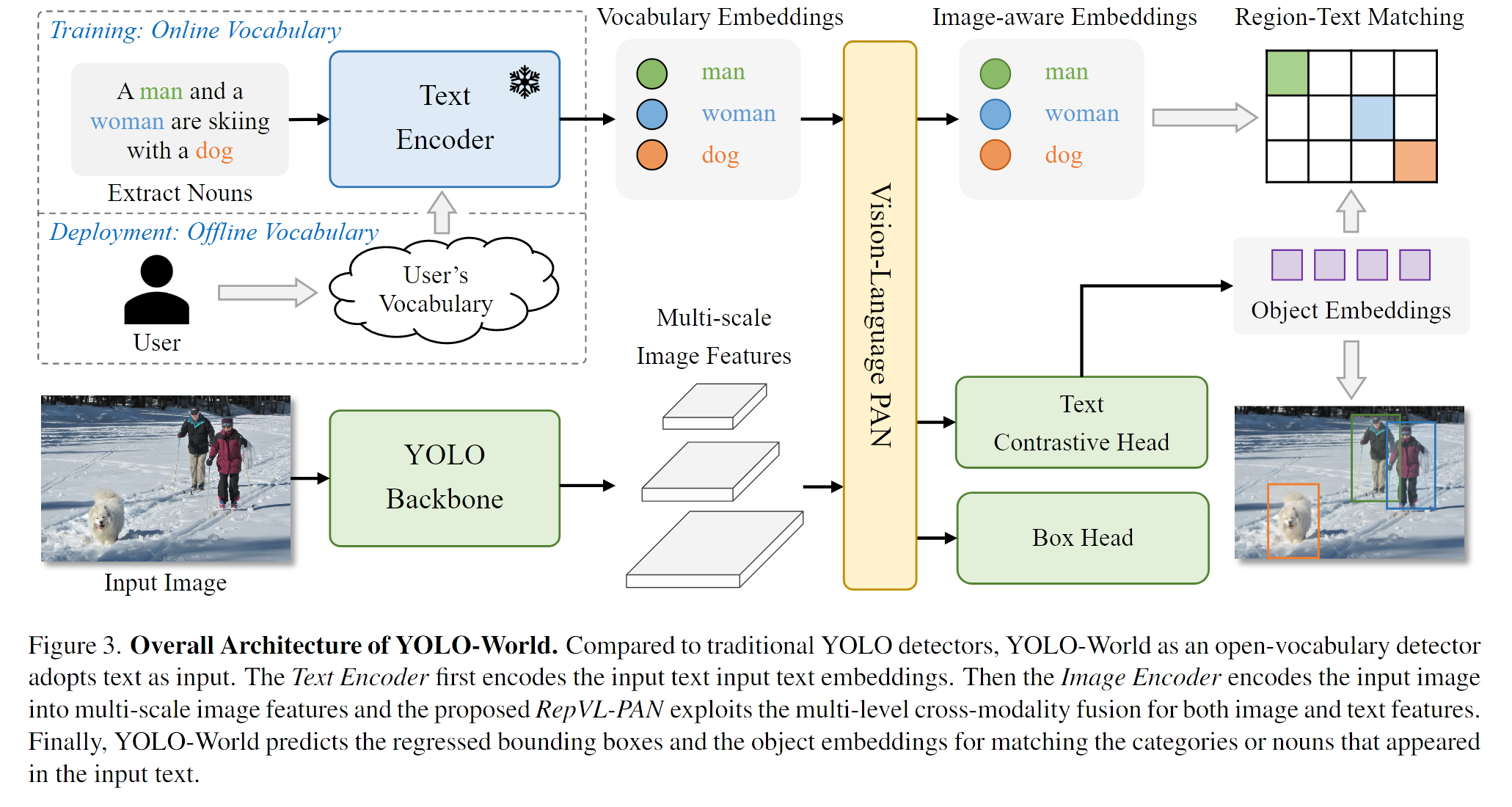
原文:[which consists of a YOLO detector, a Text Encoder, and a Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN).]
标注:YoloWorld的三个部分
原文:[YOLO Detector. YOLO-World is mainly developed based on YOLOv8 [20], which contains a Darknet backbone [20, 43] as the image encoder, a path aggregation network (PAN) for multi-scale feature pyramids, and a head for bounding box regression and object embeddings.]
标注:Yolo检测器构成
原文:[Given the text T , we adopt the Transformer text encoder pre-trained by CLIP [39] to extract the corresponding text embeddings W = TextEncoder(T ) ∈ RC×D,]
标注:
原文:[we adopt the decoupled head with two 3×3 convs to regress bounding boxes {bk}K k=1 and object embeddings {ek}K k=1,]
标注:两个解耦头,分别负责分类和定位回归
原文:[We present a text contrastive head to obtain the object-text similarity sk,j by]
标注:通过公式1进行解耦
原文:[During training, we construct an online vocabulary T for each mosaic sample containing 4 images]
标注:以马赛克的方式进行训练
原文:[the user can define a series of custom prompts, which might include captions or categories.]
标注:离线运行时使用预定的prompt进行embedding
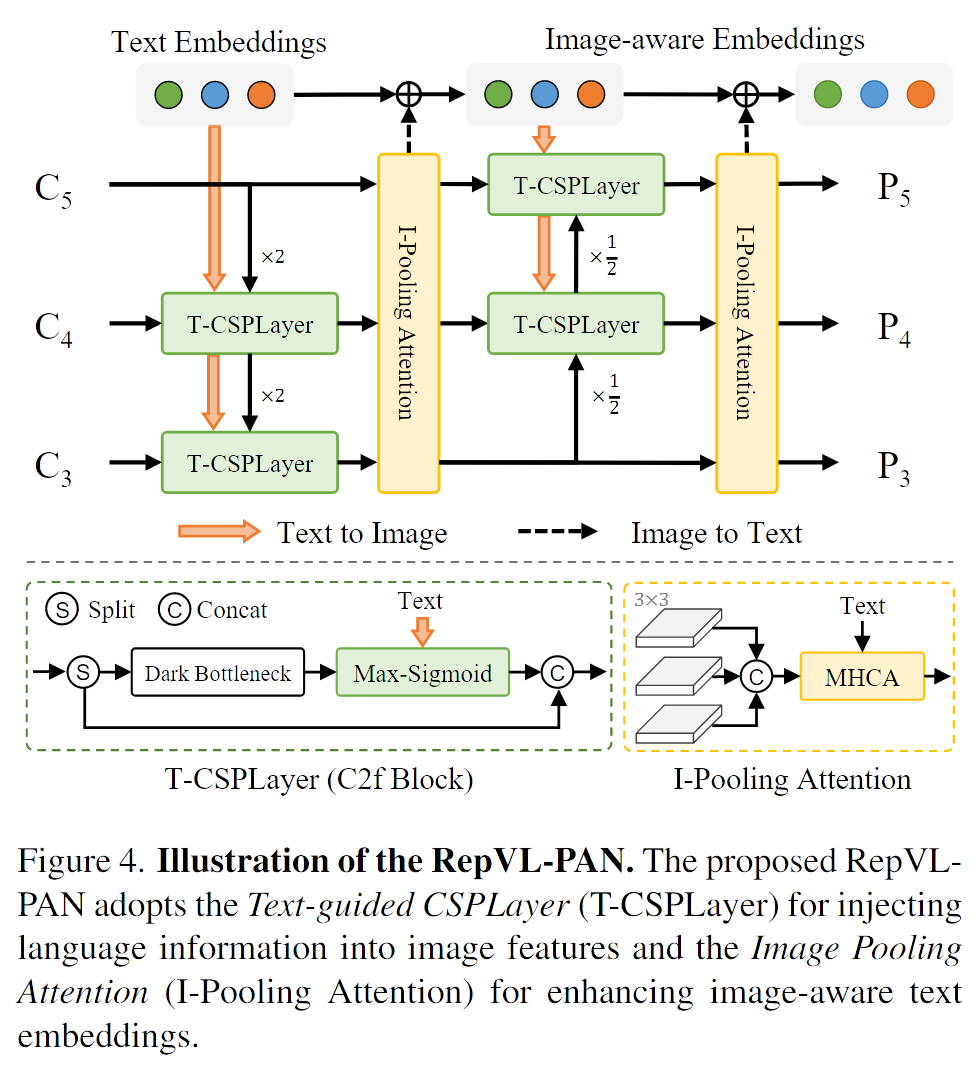
原文:[we propose the Text-guided CSPLayer (T-CSPLayer) and Image-Pooling Attention (I-Pooling Attention)]
标注:RepVL-PAN的组成
原文:[we adopt the max-sigmoid attention after the last dark bottleneck block to aggregate text features into image features by:]
标注:公式2即如何将文本信息与视觉信息融合的方法
原文:[To enhance the text embeddings with image-aware information, we aggregate image features to update the text embeddings by proposing the Image-Pooling Attention. Rather than directly using crossattention on image features,]
标注:公式3为如何将视觉信息融合入文本信息
原文:[LVIS minival]
标注:LVIS数据集是迁移过来的,应用在minival上
原文:[Table 3. Ablations on Pre-training Data. We evaluate the zeroshot performance on LVIS of pre-training YOLO-World with different amounts of data.]
标注:在添加CC3M之后情况更好,但需要额外的数据处理
原文:[Table 5. Text Encoder in YOLO-World. We ablate different text encoders in YOLO-World through the zero-shot LVIS evaluation]
标注:如果采用CLIP,frozen比较好
%% end annotations %%
%% Import Date: 2025-02-21T16:24:37.343+08:00 %%