1.Abstract&Info
1.1 Abstract
In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a $52.5$ AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean $26.1$ AP. Code will be available at \url{https://github.com/IDEA-Research/GroundingDINO}.
1.2 Info
Authors: Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang
DOI: 10.48550/ARXIV.2303.05499
Publication:
Data: 2023-01-01
2. Annotation
%% begin annotations %%
Imported: 2025-02-17 1:02 下午
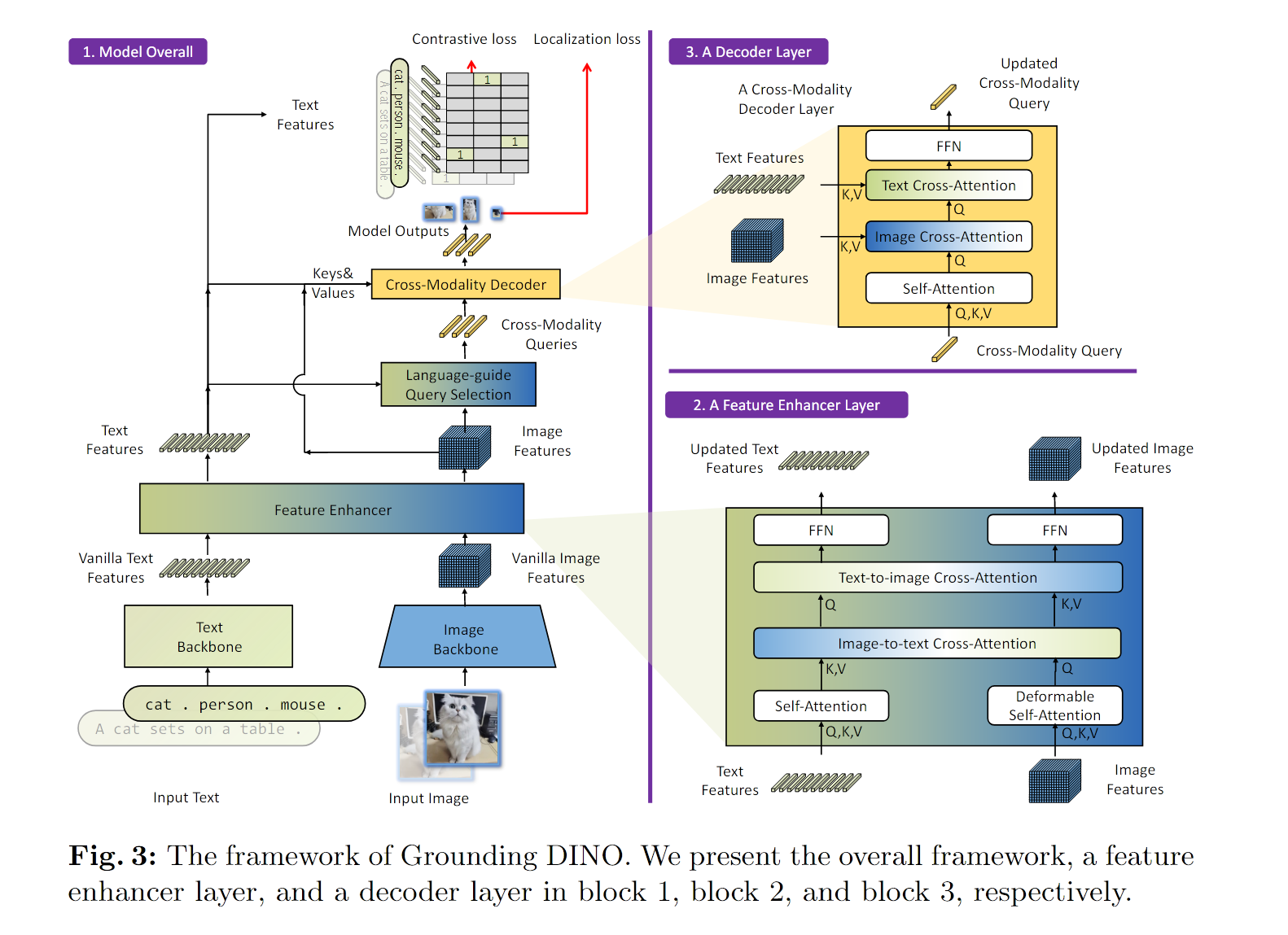
原文:[Feature fusion can be performed in three phases: neck (phase A), query initialization (phase B), and head (phase C). For example, GLIP [25] performs early fusion in the neck module (phase A), and OV-DETR [55] uses language-aware queries as head inputs (phase B). We argue that introducing more feature fusion into the pipeline can facilitate better alignment between different modality features, thereby achieving better performance.]
标注:文章认为在三个部分可以加入语义信息,越多地方加就越好
原文:[Although conceptually simple, it is hard for previous work to perform feature fusion in all three phases.]
标注:同时在三个部分加入比较困难
原文:[Unlike classical detectors, the Transformer-based detector method such as DINO has a consistent structure with language blocks.]
标注:相比基于CNN的方法,基于DETR的方法更好,因为其结构与语言模型相似
原文:[Most existing open-set models [14, 21] rely on pre-trained CLIP models for concept generalization]
标注:第一种方法,基于CLIP做概念泛化
原文:[GLIP [25] presents a different way by reformulating object detection as a phrase grounding task and introducing contrastive training between object regions and language phrases on large-scale data.]
标注:第二种,将目标检测视为描述grounding任务,在物体区域和描述之间建立联系
原文:[GLIP’s approach involves concatenating all categories into a sentence in a random order. However, the direct category names concatenation does not consider the potential influence of unrelated categories on each other when extracting features.]
标注:GLIP方法的缺点
原文:[To mitigate this issue and improve model performance during grounded training, we introduce a technique that utilizes sub-sentence level text features.]
标注:子句级别的语义特征
原文:[]
标注:三个子设置:闭集目标检测,开集目标检测和提示目标检测
原文:[]
标注:
原文:[INq = TopNq (Max(−1)(XI X⊺ T )). (1)]
标注:被选取的图像特征
原文:[Each cross-modality query is fed into a self-attention layer, an image cross-attention layer to combine image features, a text crossattention layer to combine text features, and an FFN layer in each cross-modality decoder layer.]
标注:跨模态解码器,对query进行处理,注入文本信息
原文:[Table 2: Zero-shot domain transfer and fine-tuning on COCO. *]
标注:zeroshot COCO结果
原文:[It eliminates the influence between different category names while keeping per-word features for fine-grained understanding.]
标注:移除了不必要的类别名间影响
原文:[]
标注:闭集:COCO
原文:[]
标注:开集:zero-shot COCO, LVIS, ODinW
原文:[]
标注:提示目标检测:RefCOCO/+/g
原文:[Using BERT as our text encoder,]
标注:文本编码器:BERT
原文:[Table 3: Model results on LVIS.]
标注:LVIS结果
原文:[Table 4: Model results on the ODinW benchmark.]
标注:ODinW结果
%% end annotations %%
%% Import Date: 2025-02-17T13:19:36.595+08:00 %%